🥷 [S2] Challenge 29
Just KNIME It, Season 2 / Challenge 29 reference
Challenge question
Challenge 29: Table Tennis Tournament
Level: Medium
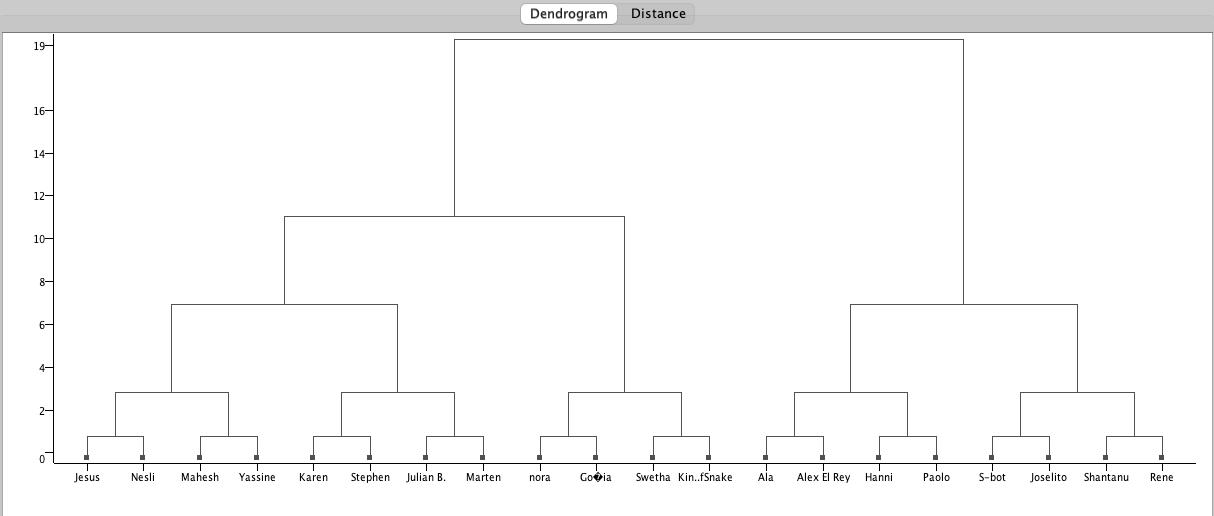
Description: You work for a Berlin startup and it's Friday night. A table tennis tournament with your colleagues is due! The following problem comes up: how to randomly split all your co-workers in random teams of two players, and then randomly define the direct elimination matches as a dendrogram? Hint: You can use the Hierarchical Cluster Assigner in this challenge.
Author: Paolo Tamagnini
Problem analysis
The main objective of this question is to create a tournament tree. Let's start by examining the data. The data consists of the names of the participating athletes and their historical performance results.
Email Address | Your Name or Nickname | Score |
|---|---|---|
| gosia@fakedomain.com | Go�ia | 93.33 |
| nora@fakedomain.com | nora | 96.73 |
| nagarjun@fakedomain.com | KingOfSnake | 101.27 |
| swetha@fakedomain.com | Swetha | 99.12 |
| stephen@fakedomain.com | Stephen | 97.12 |
| karen@fakedomain.com | Karen | 109.90 |
In this KNIME challenge, we will present the final result in the form of a tournament tree.
This question is interesting because it reflects the complexity of a real-world problem. Although the data is simple, analyzing and managing it is not. We can use hierarchical clustering to group individuals based on their performance and match players with similar competitive levels against each other. This ensures that individuals with average levels compete against each other, while those with higher levels face off, promoting fairness.
However, this seemingly fair rule gives rise to other fairness issues. For instance, in a single elimination tournament like some football Cup, if Argentina and France face each other in the first round, one team will be eliminated right away, which is undesirable. Ideally, we want to see the strongest teams in the final.
In other words, while we use historical achievements to group individuals fairly within the same level, we neglect fairness towards those at higher levels. It took them more time and effort to get there.
In real world, we have ample data at our disposal, and our decision-making heavily relies on it. However, the choice of which data to use and which to disregard directly impacts our final result. In this case, we won't consider the "Score" data and instead group individuals randomly.
Of course, using random methods is an easier approach, but we can go further. For example, if there are initially 10 groups of two individuals each, we can place the person with the highest score in Group 1 and the second-place individual in Group 10. This way, the first and second-place finishers may meet at a later stage. Real tournaments generate complex or simple tournament graphs based on different objectives and constraints, such as financial or time limitations. You can see examples of this complexity on the Tournament Management website challonge.
Any thoughts?
Nevertheless, for a small group of colleagues playing a game, a simpler and more interactive approach would be to write numbers on table tennis balls to represent the groups, place the balls in a box, and have everyone draw a ball to determine their position in the tournament tree.