🥷 [S2] Challenge 19
Just KNIME It, Season 2 / Challenge 19 reference
Challenge question
Challenge 19: Dealing with Diabetes
Level: Easy or Medium
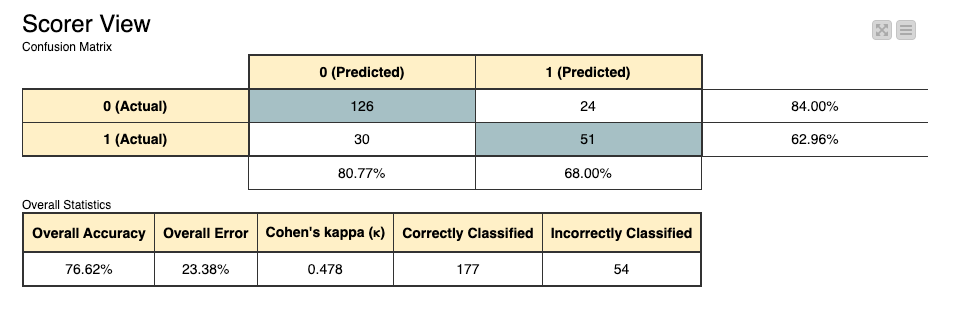
Description: In this challenge you will take the role of a clinician and check if machine learning can help you predict diabetes. You should create a solution that beats a baseline accuracy of 65%, and also works very well for both classes (having diabetes vs not having diabetes). We got an accuracy of 77% with a minimal workflow. If you'd like to take this challenge from easy to medium, try implementing:
Author: Victor Palacios
Dataset Story
The dataset is part of the large dataset held at the National Institutes of Diabetes-Digestive-Kidney Diseases in the USA. Data used for diabetes research on Pima Indian women aged 21 and over living in Phoenix, the 5th largest city in the State of Arizona in the USA. The target variable is specified as "outcome"; 1 indicates positive diabetes test result, 0 indicates negative. Someone has already been conducted on this dataset on Kaggle, so we won't delve into it too much here.
Workflow
The dataset consists of only 768 records. If we divide it into a training set and a test set, the amount of data available for training will be further reduced. Additionally, there is an issue of data imbalance in the results, meaning that there are fewer instances of people with diabetes compared to those without. In such cases, we need to utilize data synthesis techniques.
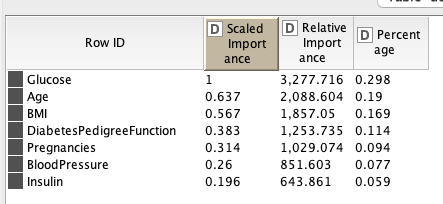
Because the data is unbalanced, we stratified the data into training and testing sets. Then, we used the SMOTE method to synthesize the data. Finally, we applied the RF algorithm from H2O for classification and obtained the final results.
SMOTE
What is SMOTE
SMOTE, which stands for Synthetic Minority Over-sampling Technique, is a statistical technique used to increase the amount of minor classes in imbalanced machine learning datasets.
In many real-world classification problems, there may be a significant imbalance in the number of instances for each class – some classes may have much fewer instances than others (known as minority classes). This can cause machine learning algorithms to be biased towards majority classes, resulting in poor predictive performance for minority classes.
SMOTE works by generating synthetic instances of the minority class, rather than simply oversampling the minority class or undersampling the majority class. It selects instances that are close in the feature space, drawing a line between the instances in feature space and creating a sample at a point along that line. This provides a more nuanced method of increasing the presence of the minority class in the dataset, and can lead to improved model performance.
Pros and Cons
SMOTE indeed has several advantages and disadvantages.
Advantages of SMOTE:
- Overcomes the Overfitting Problem: Overfitting is a common problem when dealing with imbalanced datasets. SMOTE helps to alleviate this risk by generating synthetic examples rather than replicating instances.
- Solves the Issues of Under-sampling: While under-sampling helps to balance the data, it results in losing important data points from the majority class that could be extremely important. With SMOTE, no such information from the majority class is lost.
- Improved Predictive Performance: By balancing class distribution through the generation of synthetic instances, SMOTE can improve the performance of machine learning models, particularly for the minority class.
Disadvantages of SMOTE:
- Not Effective for High Dimensional Data: If the dataset is high dimensional, SMOTE might not perform well since it may end up introducing noise.
- Increases the Likelihood of Overfitting: If the synthetic data is generated without a sufficient understanding of the data distributions, the model could potentially overfit the synthetic data.
- Generation of Noisy Samples: SMOTE can generate synthetic points that are not necessarily representative of valid points in the original feature space, resulting in noisier data.
Any thoughts?
- The dataset contains several erroneous values, some of which are clearly impossible, such as Zero blood pressure. I'm not sure how to handle this situation in the best way or if it would improve the metrics. I attempted a simple approach to address the issue, but it did not improve the final metrics. I'm unsure of the reason behind this.
- There are also other data synthesis methods that I'm not sure would be effective. Personally, I am somewhat opposed to data synthesis methods because they introduce noisy data. However, given the small size of this dataset, I haven't found any other alternatives.
- It would be beneficial to have more features, such as the person's regular blood sugar/insulin levels, to make comparisons.