🥷 [S2] Challenge 06
Just KNIME It, Season 2 / Challenge 06 reference
Challenge 06: Airline Reviews
Level: Hard
Description: You work for a Marketing agency that monitors the online presence of a few airline companies to understand how they are being reviewed. You were asked to identify whether a tweet mentioning an airline is positive, neutral, or negative, and decided to implement a simple sentiment analysis classifier for this task. What accuracy can you get when automating this process? Is the classifier likely to help company reviewers save their time? Note: Given the size of the dataset, training the classifier may take a little while to execute on your machine (especially if you use more sophisticated methods). Feel free to use only a part of the dataset in this challenge if you want to speed up your solution. Hint 1: Check our Textprocessing extension to learn more about how you can turn tweets' words into features that a classifier can explore. Hint 2: Study, use, and/or adapt shared components Enrichment and Preprocessing and Document Vectorization (in this order!) if you want to get a part of the work done more quickly. They were created especially for this challenge. Hint 3: Remember to partition the dataset into training and test set in order to create the decision tree model and then evaluate it. Feel free to use the partitioning strategy you prefer.
General Idea
Because sentiment analysis is a very general natural language processing task. So I didn't spend much time building from the ground up. I just used large language models (LLMs).
When I finally got the result, I was actually not very satisfied. Because I think that for such a specific task, such a score is actually a bit low. So I did some error analysis.
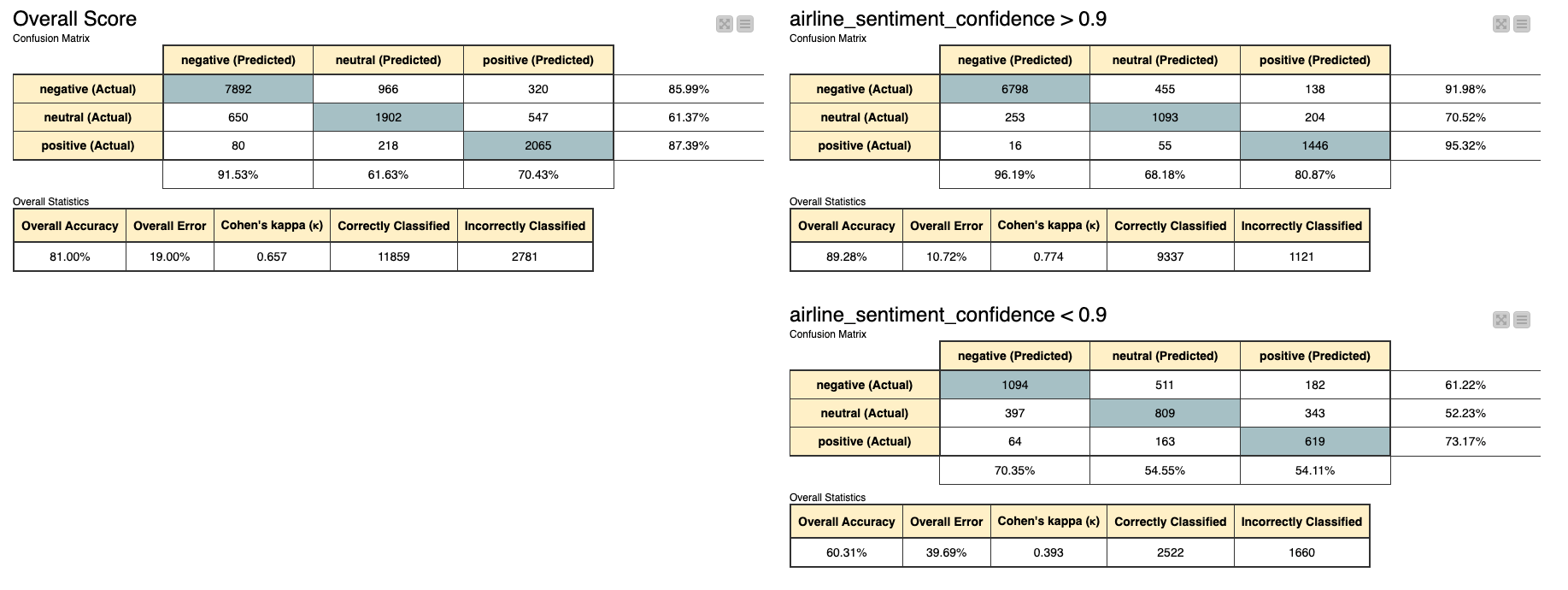
Error analysis
Because there are some indicators of sentiment analysis determinism in the raw data, like airline_sentiment_confidence. So I split this data into two categories with a bounded 0.9. Then compare the score. Although there have been some improvements, I am still not very satisfied with the accuracy.
So I wanted to see what the raw data looked like.
First, I sorted the original data in ascending order based on airline_sentiment_confidence. That is, I put the tweets at the top where it's not sure what kind of emotion it was.
If the prediction label does not match the raw data, I label it green.
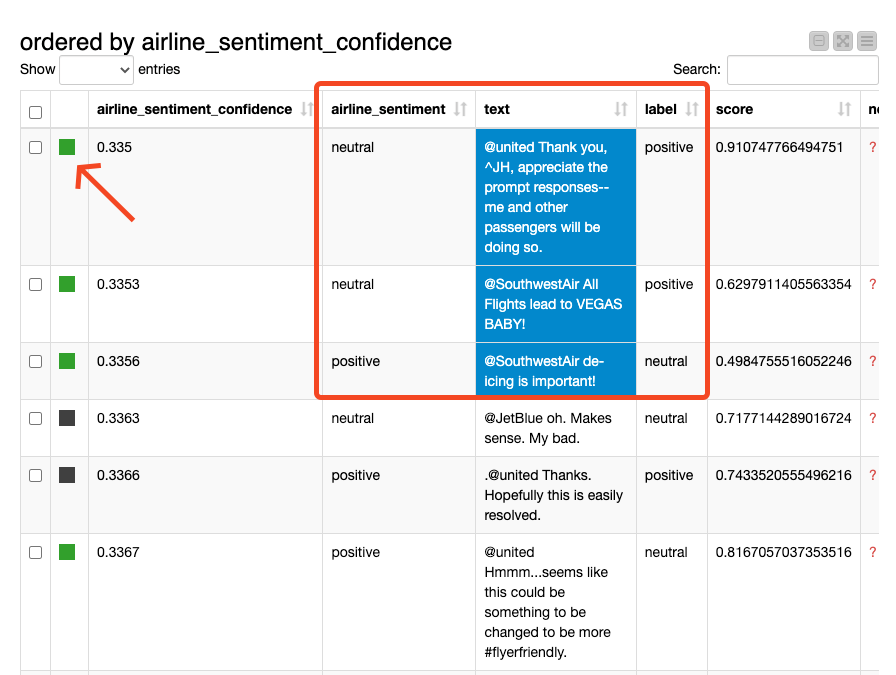
Let's take a look at the first three tweets.
- @united Thank you, ^JH, appreciate the prompt responses--me and other passengers will be doing so.
- @SouthwestAir All Flights lead to VEGAS BABY!
- @SouthwestAir de-icing is important!
In the raw data, there are classified as:
- neutral/0.335
- neutral/0.3353
- positive/0.3356
LLMs classified them as:
- positive/0.9107
- positive/0.6297
- neutral/0.4984
I think I found the reason, some of the annotations in the raw data are inaccurate.
Based on the score of the LLMs, I also did the sorting.
- @USAirways can't even get on hold to wait to speak to someone-awesome
- raw data: negative/0.6907
- LLMs: positive/0.3522
- @VirginAmerica I was really looking forward to my flight. can you let me know when it will be rescheduled? #diehardvirgin
- raw data: negative/0.664
- LLMs: neutral/0.3548
- @united I need #United to be a better airline!!
- raw data: negative/0.7125
- LLMs: neutral/0.3689
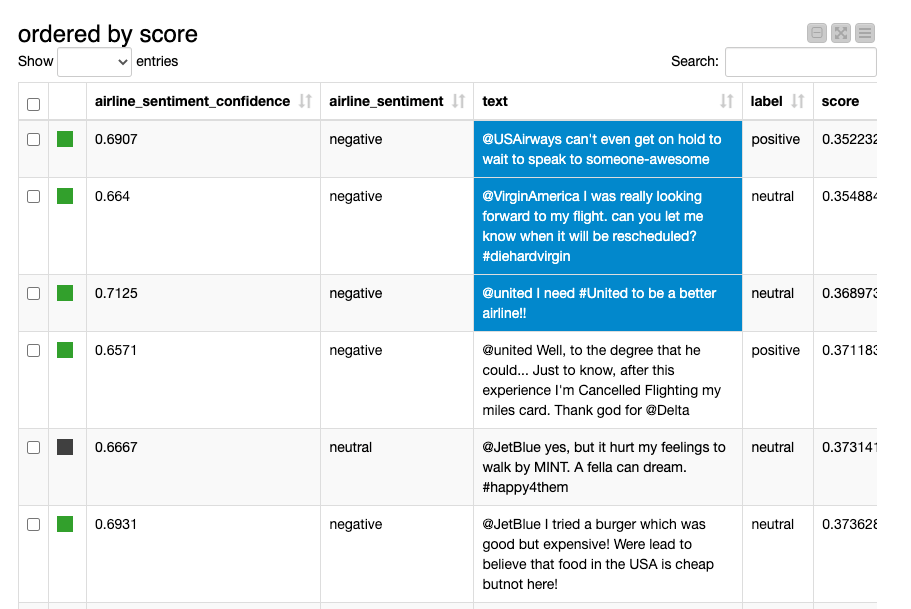
I think I know what the problem is.