🥷 [S2] Challenge 20
Just KNIME It, Season 2 / Challenge 20 reference
Challenge question
Challenge 20: Topics in Hotel Reviews
Level: Hard
Description: You work for a travel agency and want to better understand how hotels are reviewed online. What topics are common in the reviews as a whole, and what terms are most relevant in each topic? How about when you separate the reviews per rating? A colleague has already crawled and preprocessed the reviews for you, so your job now is to identify relevant topics in the reviews, and explore their key terms. What do the reviews uncover? Hint: Topic Extraction can be very helpful in tackling this challenge. Hint 2: Coherence and perplexity are metrics that can help you pick a meaningful number of topics.
Author: Aline Bessa
Here are some of the key concepts involved in this challenge.
LDA
In the context of data science, LDA typically refers to Latent Dirichlet Allocation. It's a generative statistical model commonly used in natural language processing and machine learning.
LDA is used to classify text in a document to a particular topic. It builds a topic per document model and words per topic model, implemented via a probabilistic graphical model.
The basic idea of LDA is that documents are represented as random mixtures over latent topics, where each topic is characterized by a distribution over words. It assumes that the order of the words doesn't matter (bag of words assumption).
LDA can be used in various tasks like automated tagging systems, content recommendation, and text classification among others.
So, where does the term "Dirichlet" come from?
The "Dirichlet" in Latent Dirichlet Allocation (LDA) refers to the Dirichlet probability distribution. The Dirichlet distribution is a family of continuous multivariate probability distributions parameterized by a vector of positive reals. It is a multivariate generalization of the beta distribution. It's often used in Bayesian statistics and machine learning.
In the LDA model, the Dirichlet distribution is used to model the distribution of topics in documents and the distribution of words in topics. It's particularly suitable for this application because it's a multivariate distribution, allowing for the representation of multiple topics within a single document and multiple words within a single topic. Furthermore, the Dirichlet distribution can be used to model the variability among these distributions — for example, how much topics vary among documents or how much word usage varies among topics.
The Topic Extractor (Parallel LDA) node in KNIME
It is a simple parallel threaded implementation of LDA.
'Number of topics': Mainly used to set up several topics in your document to detect. Obviously, for some simple article content, such as the evaluation text of the product, there must be very few topics in it, mainly focusing on which characteristics of the product are satisfied or dissatisfied. Another example is a literary review, which may involve more topics, including topics about the content of its comments, topics that he wants to extend, and so on.
Number of words per topic: This is not a parameter of the model, but an output. The LDA model will generate a number of whole words from the corpus vocabulary that are strongly associated with each topic. The number of words used to describe a given topic can affect the interpretability of the topic. Too few words, and the topic might be too broad to be meaningful. Too many words, and you might start to include words that aren’t really critical to the definition of the topic.
Regarding the terms 'alpha' and 'beta', they primarily refer to the parameters used in LDA.
Alpha: This parameter represents document-topic density. With a higher alpha, documents are made up of more topics and with lower alpha, documents contain fewer topics. In other words, alpha controls the mixture of topics for any given document. If alpha is large, each document is likely to contain a mixture of most of the topics, and not just one. If alpha is small, each document is likely to contain a mixture of just a few of the topics.
Beta: This parameter indicates topic-word density. Higher beta means that each topic will contain a mixture of most of the words in the corpus, and with a lower beta, each topic will contain a mixture of fewer words. In other words, it controls the distribution of words for a given topic. The higher the beta, the more words will be shared among topics. The lower the beta, the more distinct the words will be per topic.
For the adjustment of these parameters, some optimization algorithms can be used, but these optimization algorithms need to know what situation (indicator) is adjusted or not. In KNIME, the specific optimization can use the 'Parameter Optimization Loop Start' related node structure (the nodes identified by 1,2 in the figure) to turn the variables to be adjusted into flow variables and put them into downstream LDA nodes. The specific adjustment indicator is calculated by the nodes identified by 3 and 4 in the figure. In the graphical result of Figure 5, you can see in what combination of these parameters will achieve an optimal indicator. For example, in the line chart, you can see that when the topic (k) you want to detect is 2, the 'Semantic Coherence' metric is the highest and the 'Perplexity' indicator is the lowest.
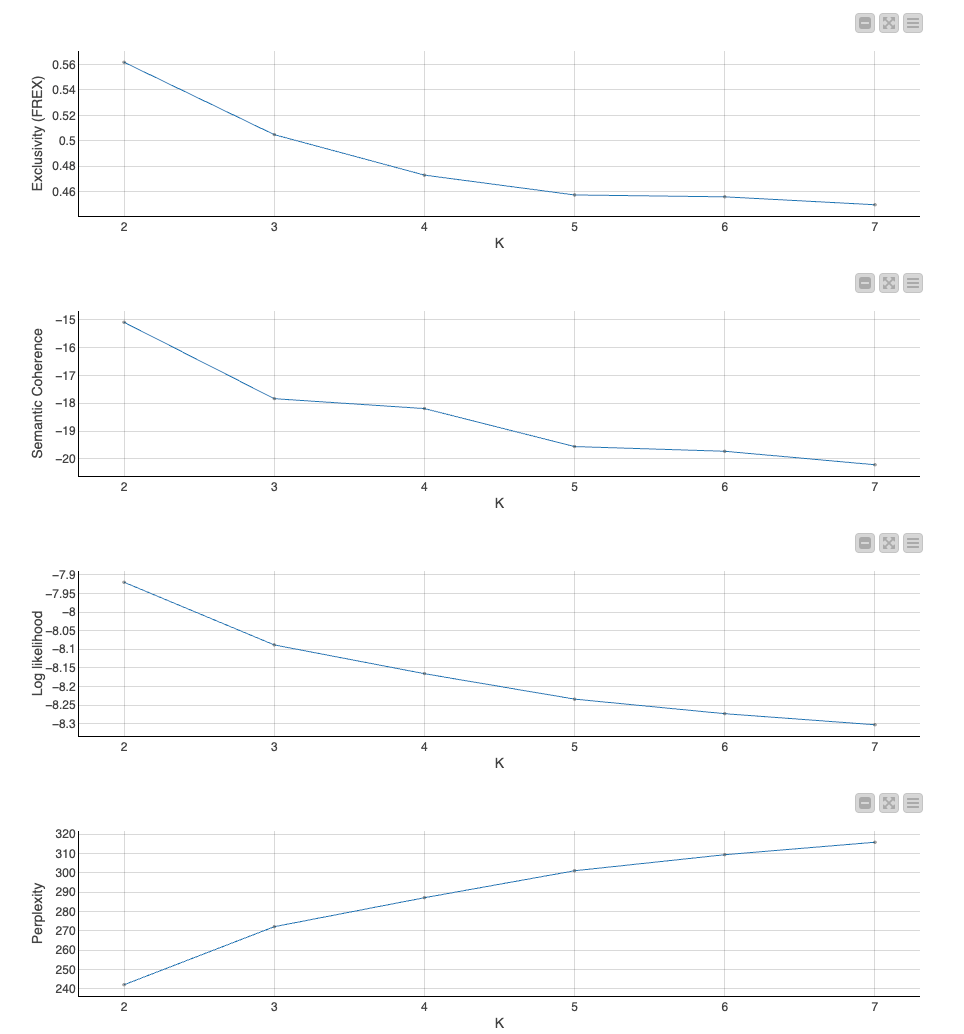
About indicators 'Semantic Coherence' and 'Perplexity'
Coherence Score
The Coherence Score is a statistical measure used in topic modeling to determine the quality of the learned topics. It is a measure of the degree of semantic similarity between high scoring words in the topic.
The concept behind the Coherence Score is that the more similar the words in a topic are, the more coherent the topic is, and accordingly, the better the topic model. The score is typically used to compare different models to each other, in order to determine which model has better-learned, more meaningful topics.
Several types of Coherence Scores exist, such as UMass and c_v, which use different mathematical calculations to measure coherence. UMass takes into account the occurrence of word pairs in documents, while c_v considers vectors of word distributions.
If a model identifies a topic with the words 'apple', 'banana', 'orange', and 'grape', and we find that these words frequently occur together in the text corpus, the topic is likely to be coherent (maybe a topic about fruits). Hence, the Coherence Score for this topic would be high.
It's important to note that while the Coherence Score can provide useful insights, it shouldn't be the sole determinant of a model's quality as it might not always align perfectly with human evaluations of topic quality. A high coherence score generally suggests a good topic model, but does not guarantee that the topics will be interpretable or meaningful in a real-world context.
Perplexity
Perplexity is a statistical measure that is widely used in Natural Language Processing (NLP) for evaluating probabilistic models, especially in language modeling and topic modeling.
The concept of perplexity essentially measures how well a probability distribution or probability model predicts a sample. It might be interpreted as a measure of the model's "surprise." A lower perplexity score indicates better performance of the model because that means the model is less "surprised" or "perplexed" by the test data it encounters. Therefore, in topic modeling or language modeling, a lower perplexity score often signifies that the model has better generalization performance.
Mathematically, perplexity is defined as the exponentiation of the entropy (which measures the unpredictability or randomness of data), given by the following formula:
Perplexity and entropy are both measures used in the field of information theory and machine learning to gauge how well our models are doing.
Entropy is a measure of uncertainty or randomness of information. Let's consider a text prediction model like predictive text on your phone. Based on the previous words you've typed, the model predicts the next word.
Let's say you start a sentence with "How are", and the model has to predict the next word. If it has a vocabulary of 1000 potential words, and knowing nothing else, it assigns equal probability to each. Then the perplexity of this model would be 1000, essentially saying the model is as "confused" as a uniform random guesser.
Now let's say that over time, the model has learned "you" is the most likely next word, with a probability of 0.6. The remaining probability is spread evenly across 999 other words. Now, the perplexity would be significantly lower, indicating the model’s “confusion” is less.
Any thoughts?
- There are some nodes that behave inconsistently in KNIME 4.7 and KNIME 5.1, which is a bit troublesome. I need to plan my KNIME version migration plan
- There are some NLP components (KNIME official) that are too complicated. For example, I just use a component called 'Topic Explorer View', and when the topic number of the upstream node 'Topic Extractor (Parallel LDA)' is set to 2, this node does not work, because it is too complicated, and there is no time to find the specific reason.
- And 'KNIME Deeplearning4J Integration (64bit only)', I don't know which component needs it. I watched it download some CUDA stuff, but I didn't have any GPU on my Mac. It's complicated anyway, and I don't want to figure out why that's the case.