🥷 [S2] Challenge 25
Just KNIME It, Season 2 / Challenge 25 reference
Challenge question
Challenge 25: Detecting the Presence of Heart Disease
Level: Medium
Description: You work as a data scientist for a healthcare company attempting to create a predictor for the presence of heart disease in patients. Currently, you are experimenting with 11 different features (potential heart disease indicators) and the XGBoost classification model, and you noticed that its performance can change quite a bit depending on how it is tuned. In this challenge, you will implement hyperparameter tuning to find the best values for XGBoost's Number of Boosting Rounds, Max Tree Depth, and learning rate hyperparameters. Use metric F-Measure as the objective function for tuning.
Author: Keerthan Shetty
Dataset: Heart Disease Data in the KNIME Hub
test KNIME AI Assistant
I tested KNIME Analytics Platform 5.1.1, which was released on September 14, 2023, for this challenge. I also explored the new KNIME AI Assistant extension. The extension comprises two features: QA and Build. The QA feature resembles the Q&A section in ChatGPT, allowing users to ask questions in a conversational manner. On the other hand, the Build feature enables users to describe the desired task, and the plugin constructs the corresponding workflow. This extension, proposed in April and May of this year, is still in its early stages, so it is advisable not to expect too much from it. Nevertheless, we can peek potential future use cases through this extension.

Once I had the data prepared, I proceeded to use the Build feature. Here is a brief prompt of the problem:
"Using the current CSV reader's data, help me implement hyperparameter tuning to determine the optimal values for XGBoost's Number of Boosting Rounds, Max Tree Depth, and learning rate hyperparameters. The objective function for tuning should be the F-Measure metric."
After providing this description, the workflow building process began. However, after adding two nodes, an error message appeared, indicating a problem. It seemed that there was an issue.
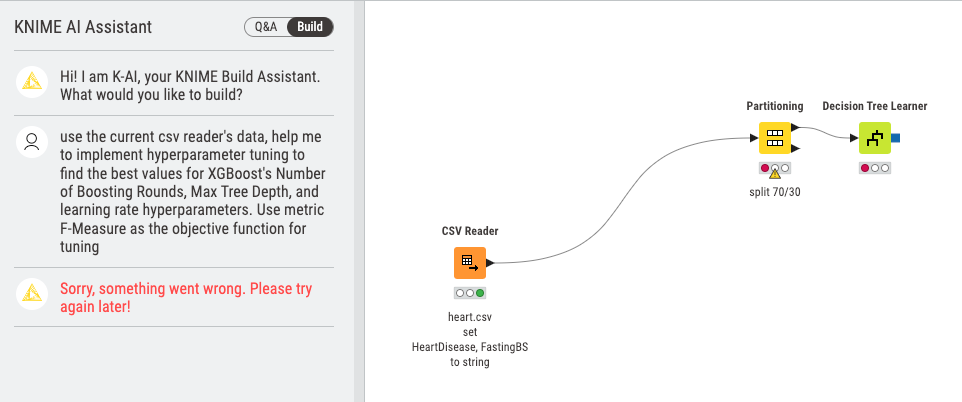
I attempted again, this time adjusting the description:
"Using the current CSV reader's data:
- Partition the data.
- Utilize the hyperparameter tuning node, focusing on 'Number of Boosting Rounds, Max Tree Depth, and learning rate.' Then, send the variable to the XGBoost node and obtain the score.
- Find the best hyperparameters."
Unfortunately, it still did not work as expected. However, it is worth noting that the AI Assistant provided a detailed comment about SVM node.
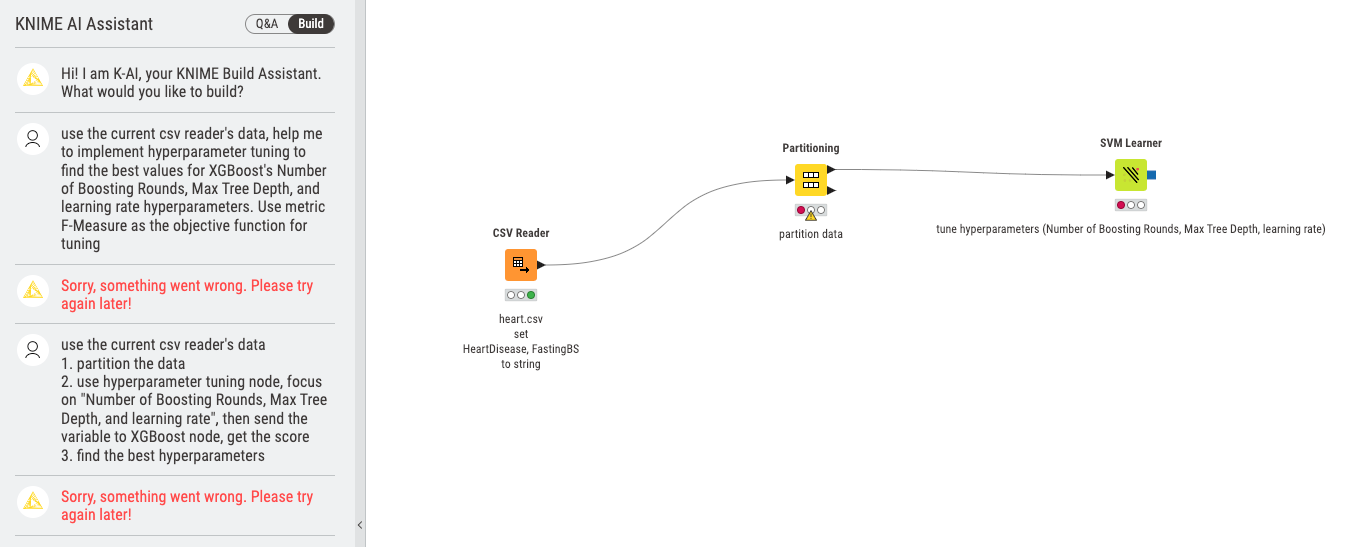
Realizing that I had not installed the necessary extensions, including xgboost, I wondered if the AI Assistant required their installation to be success. After installing the extensions, the build process is almost the same. It turned out that the AI model chosen by KNIME may have been somewhat weak.
In the end, I had to complete the task myself. The question was relatively simple, as long as one understands how to use stream variables and the Parameter Optimization Loop node. There is not much more to say about it.

Any thoughts?
- "KNIME AI Assistant" need login everytime I restart the KNIME, this is a bit annoying.
- OpenAI has already offered training on custom data, and I anticipate that KNIME AI will become better in near future.
- For KNIME documents, using a less powerful LLMs model and leveraging RAG to retrieve answers may be beneficial.
- If someone desires to use a more advanced model like GPT4, allowing users to input their own key and shoulder the associated cost could enhance this extension's capabilities.
- The user interface for QA is not ideal and requires further refinement. In summary, the future holds great promise.